
El objetivo de este articulo es explicar lo que hay detrás de una red neuronal artificial, esas cajas negras en las que la mayoría de veces simplemente creamos las estructura, introducimos un valor de entrada y por arte de magia obtenemos una predicción de un valor que será mas o menos cercano a la realidad.
Pero detrás de esa magia hay una serie de operaciones matemáticas que siguen una lógica muy estructurada y que en las próximas lineas voy a explicar de una manera practica usando, por supuesto las matemáticas y el lenguaje de programación Python, donde crearemos una red neuronal propia que sea capaz de aprender un sistema de clasificación
¿Que es una red neuronal?
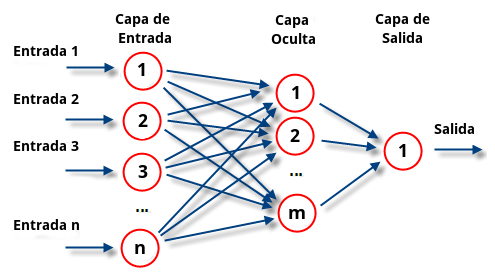
- Una red neuronal se define como un sistema que consiste en una serie de elementos todos interconectados, llamados «neuronas», que se organizan en capas que procesan la información utilizando respuestas de estado dinámico a entradas externas.
- En el contexto de esta estructura, la capa de entrada introduce patrones en la red neuronal que tiene una neurona para cada componente presente en los datos de entrada y se comunica a una o más capas ocultas, se considera capas ocultas a todas las capas de la red exceptuando la de entrada y salida. Es en las capas ocultas donde sucede todo el procesamiento, a través de un sistema de conexiones caracterizado por pesos y sesgos (comúnmente conocidos como W yb)
¿Como funciona?
- Con el valor de entrada que recibe la neurona se calcula una suma ponderada agregando también el sesgo y de acuerdo con el resultado y una función de activación preestablecida (las cuales veremos a continuación), se decide la activación o excitación de la neurona. Posteriormente, la neurona transmite la información a otras neuronas conectadas en un proceso llamado «PassFoward». Al final de este proceso, la última capa oculta está vinculada a la capa de salida que tiene una neurona para cada posible salida deseada.


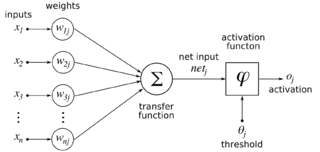
Funciones de Activación
Se utiliza para determinar la salida de la red neuronal como sí o no. Mapea los valores resultantes entre 0 a 1 o -1 a 1 .Las funciones de activación se pueden dividir básicamente en 2 tipos:
- Función de activación lineal : Las cuales ya no se usan en el Deep Learning, ya que la salida de las funciones no estará confinada entre ningún rango y la suma de diferentes funciones lineales sigue siendo una función lineal acotando así la activación de la neurona.
- Funciones de activación no lineal: Son las usadas en las redes neuronales, como veremos a continuación estas funciones permiten un acotamiento de los datos de salida. Algunos ejemplos son al función sigmoide o tangente hiperbólica
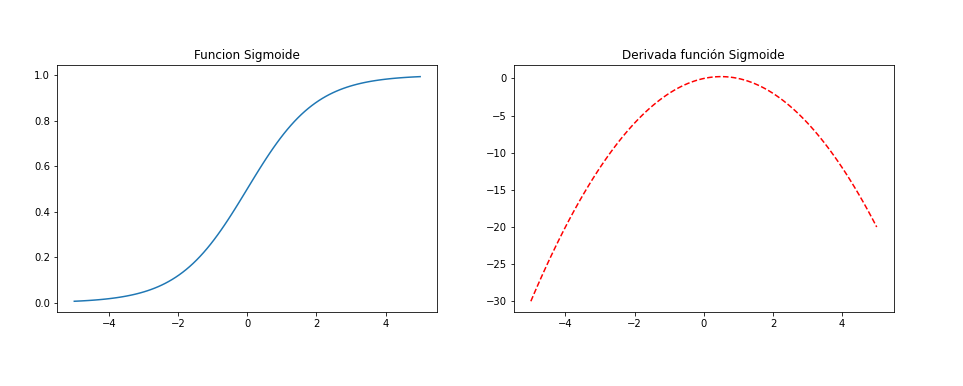
Función Sigmoide
- La razón principal por la que usamos la función sigmoide es porque existe entre (0 a 1). Por lo tanto, se usa especialmente para modelos en los que tenemos que predecir la probabilidad como un resultado. Dado que la probabilidad de cualquier cosa existe solo entre el rango de 0 y 1


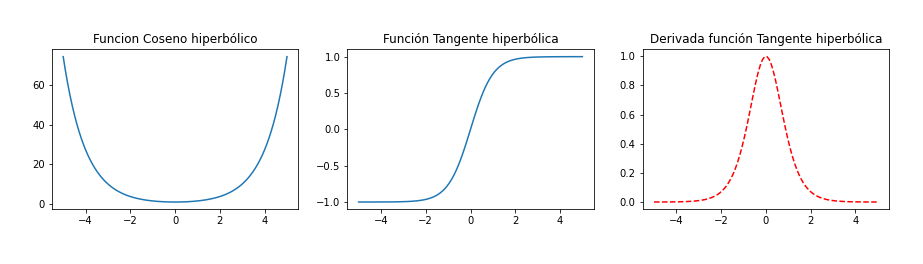
Función Tangente hiperbólica o Gaussiana
- Es una función similar a la Sigmoide pero produce salidas en escala de [-1, +1]. Además, es una función continua. En otras palabras, la función produce resultados para cada valor de x.



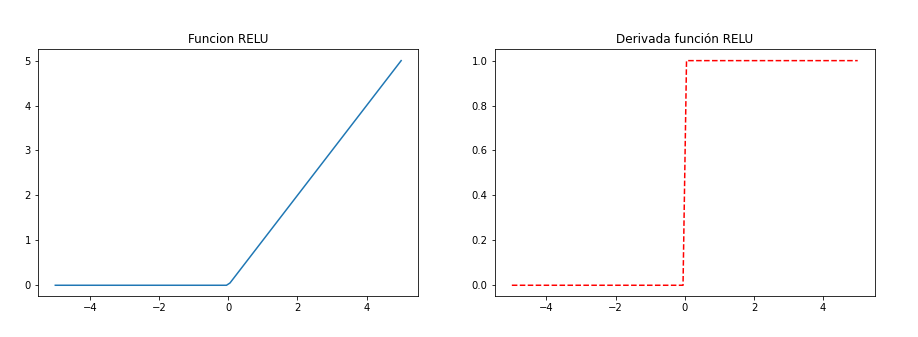
Función RELU (Rectified Lineal Unit)
- ReLU es la función de activación más utilizada en el mundo en este momento. Desde entonces, se utiliza en casi todas las redes neuronales convolucionales o el aprendizaje profundo.
- Como puedes ver, ReLU está medio rectificado (desde abajo). f(z) es cero cuando z es menor que cero y f(z) es igual a z cuando z es superior o igual a cero.
- Es una función usada en las capas ocultas de nuestra red neuronal, NO en las de salida


Creamos las funciones en Python
¿Como aprende nuestra red neuronal?
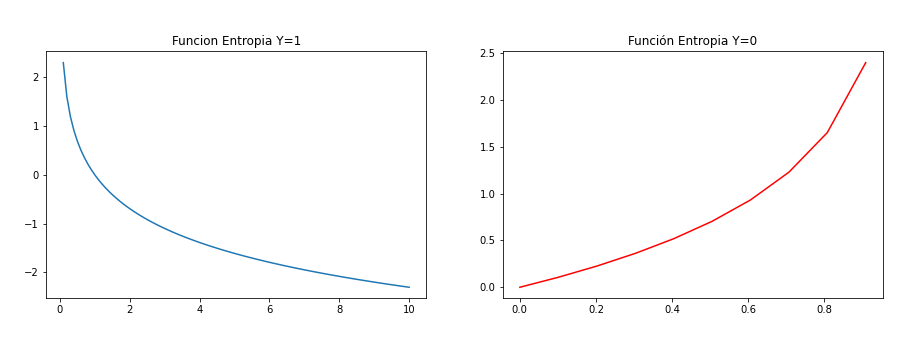
El paso final del PassForward es evaluar la salida predicha (Yr) contra una salida esperada (Yr). La salida Yr es parte del conjunto de datos de entrenamiento (x, y) donde x es la entrada (como vimos en la sección anterior). La evaluación entre Yp e Yr se realiza a través de una función de coste. Para este ejercicio hemos usado dos funciones de coste:
- MSE (error cuadrático medio)
- Entropía cruzada binaria.
Llamamos a esta función de coste C y la denotamos de la siguiente manera:



Donde el cost puede ser igual a MSE, entropía cruzada o cualquier otra función de coste. Según el valor de C, el modelo «sabe» cuánto ajustar sus parámetros (Weight y BIAS) para acercarse a la salida esperada y. Esto sucede usando el algoritmo de retropropagación o tambien conocido como Backpropagation.
Funciones de coste y sus derivadas
MSE (Error cuadrático medio)


Cross entropy binary

Estas dos expresiones podemos juntarlas en una sola para obetener una unica función de coste


Funciones de perdida en Python
BackPropagation y gradiente descendente
Backpropagation tiene como objetivo minimizar la función de coste ajustando los pesos (w) y sesgos (bias) de la red. El nivel de ajuste está determinado por los gradientes de la función de coste con respecto a esos parámetros. (derivadas)
La derivada de una función C mide la sensibilidad al cambio del valor de la función (valor de salida) con respecto a un cambio en su argumento x (valor de entrada). En otras palabras, la derivada nos dice en qué dirección va C.
El gradiente muestra cuánto debe cambiar el parámetro x (en dirección positiva o negativa) para minimizar C.
Para calcular estos gradientes usamos la tecnica de la Regla de la cadena
Derivada de la función de Coste respecto al peso
- Se puede expresar con la regla de la cadena, multiplicando la derivada del Coste respecto a la suma ponderada (z) por la derivada de (z) respecto al valor del peso (w)






Derivada de la función de Coste respecto al parametro BIAS
- Se puede expresar con la regla de la cadena, multiplicando la derivada del Coste respecto a la suma ponderada (z) por la derivada de (z) respecto al valor del BIAS (b)



La parte común en ambas ecuaciones a menudo se denomina «gradiente local» y se expresa de la siguiente manera:


Computar el error de la capa anterior

Cuando ya tenemos el desarrollo de las variables parciales podemos ajustar los parametros de nuestra red
Actualizamos el parametro de BIAS usando el Vector Gradiente


Actualizamos el parametro de pesos usando el vector Gradiente

Realizamos este proceso interativamente hasta que conseguimos minimizar el error en nuestra función de coste. Algoritmo del Gradiente Descendente
Programamos la Red neuronal en Python
Todo el proyecto disponible en:
https://github.com/jmcalvomartin/python/tree/master/projects/Create_ANN
Jorge Calvo
Profesor y Responsable de Tecnología e Innovación en Colegio Europeo de Madrid -- Asesor y Formador Tecnología Educativa -- CoFundador EuropeanValley Institución




