En este articulo me gustaría mostraros una practica con R usando el famosos dataset del Titanic. La verdad es que es un ejercicio muy conocido y donde podéis encontrar mucha documentación sobre él en la red pero a mi me apetecía mostraros como realicé esta practica de una forma, creo que sencilla, para conseguir dos modelos predictivos y saber con que eficacia un pasajero hubiera sobrevivido en el Titanic.
Antes de mostraros los vídeos donde explico de manera detallada el ejercicio, quiero mostraros los pasos que he seguido para conseguir esos modelos de machine learning. Lo primero que debéis hacer para seguirme en este ejercicio es descargaros el dataset del Titanic, para ello podéis hacerlo de diferentes repositorios, para facilitaros el trabajo os he dejado el enlace al dataset que yo uso en este ejercicio.
https://europeanvalley.es/resources/titanic/titanicdf.csv
Una vez que tenemos este archivo csv descargado en nuestro ordenador, buscaremos una carpeta de trabajo donde realizaremos la programación con RStudio. Recordaros que R es un lenguaje de programación enfocado sobre todo a la matemática y a la estadística, dos pilares fundamentales para el machine learning.
Una vez que tenemos nuestro Rstudio abierto y elegido nuestro espacio de trabajo con el archivo CSV ya podemos empezar a trabajar con el primer vídeo, el cual he titulado «Análisis y Limpieza de Datos»
En este primer video basicamente lo que haremos será preparar los datos para realziar a posteriori los modelos predictivos, para ello debemos gestionar todos esos datos nulos que nos encontremos y datos cualitativos que tendremos que convertir en cuantitativos con algunas tecnicas de Data Cleaning.
Video 1 – Preparamos los Datos del Titanic
Si habeis seguido el primer video sin problemas, ahora tendréis un dataset preparado para implementar un modelo de predicción. En este primer video hemos mostrado diferentes tecnicas para poder limpiar los datos de manera correcta, simplemente borrando columnas (variables explicativas) que tendría poca relevancia en nuestro modelo o utilizar el valor medio de una variable explicativa para colocarla en los valores nulos y así de esta manera evitar el borrado de esos datos.
Otra tecnica que hemos visto ha sido la creación de variables Dummies, como una variable cuantitativa como era el sexo del pasajero o el lugar de embarque la hemos convertido en valores booleanos para que así pueda inttrudirse en el modelo de forma cuantitativa.
Ahora en este segundo video vamos a exlpicar el modelo de Regresión Logistica, un modelo que nos sirve para clasificar una entrada (input) entre dos opciones, 1 o 0 (output).
En este escenario este modelo nos encaja perfectamente ya que el valor que queremos predecir es la supervivencia de nuestro pasajero, 1 si sobrevivió o 0 si falleció. Esta predicción se conseguie al pasar el valor de nuestras variables explicativas (edad, tarifa, embarque, hermanos..) por una función sigmoide, la cual explicamos en el siguiente video.
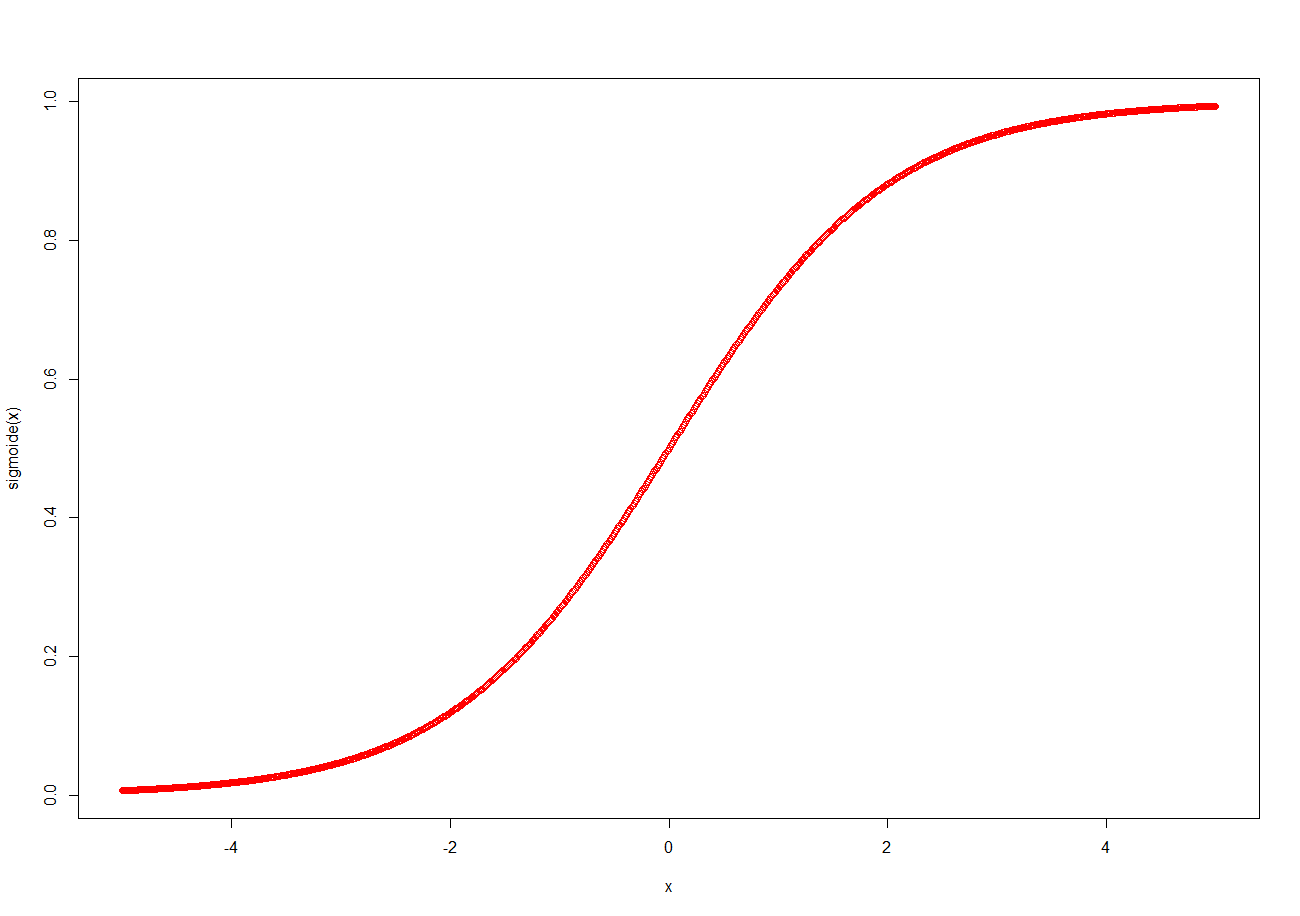
Video 2 – Modelo Regresión Logistica
Bien, ahora que ya tenemos nuestro primer modelo de predicción y hemos podido comprobar su eficacia, pore encima del 90%, lo que podemos hacer es realizar un segundo modelo y compararlos.
En este tercer video vamos a mostrar un modelo basado en un arbol de decisión, es uno de los modelos más utlizados y probablemente facil de enteder sin entrar en mucho detalle matemático.
Un árbol de decisión en Machine Learning es una estructura de árbol similar a un diagrama de flujo donde un nodo interno representa una característica (o atributo), la rama representa una regla de decisión y cada nodo hoja representa el resultado. Para medir y valorar estas reglas de decisión utiliza diversas funciones, siendo las más conocidas los Indice gini y Ganancia de información que utiliza la denominada entropía.
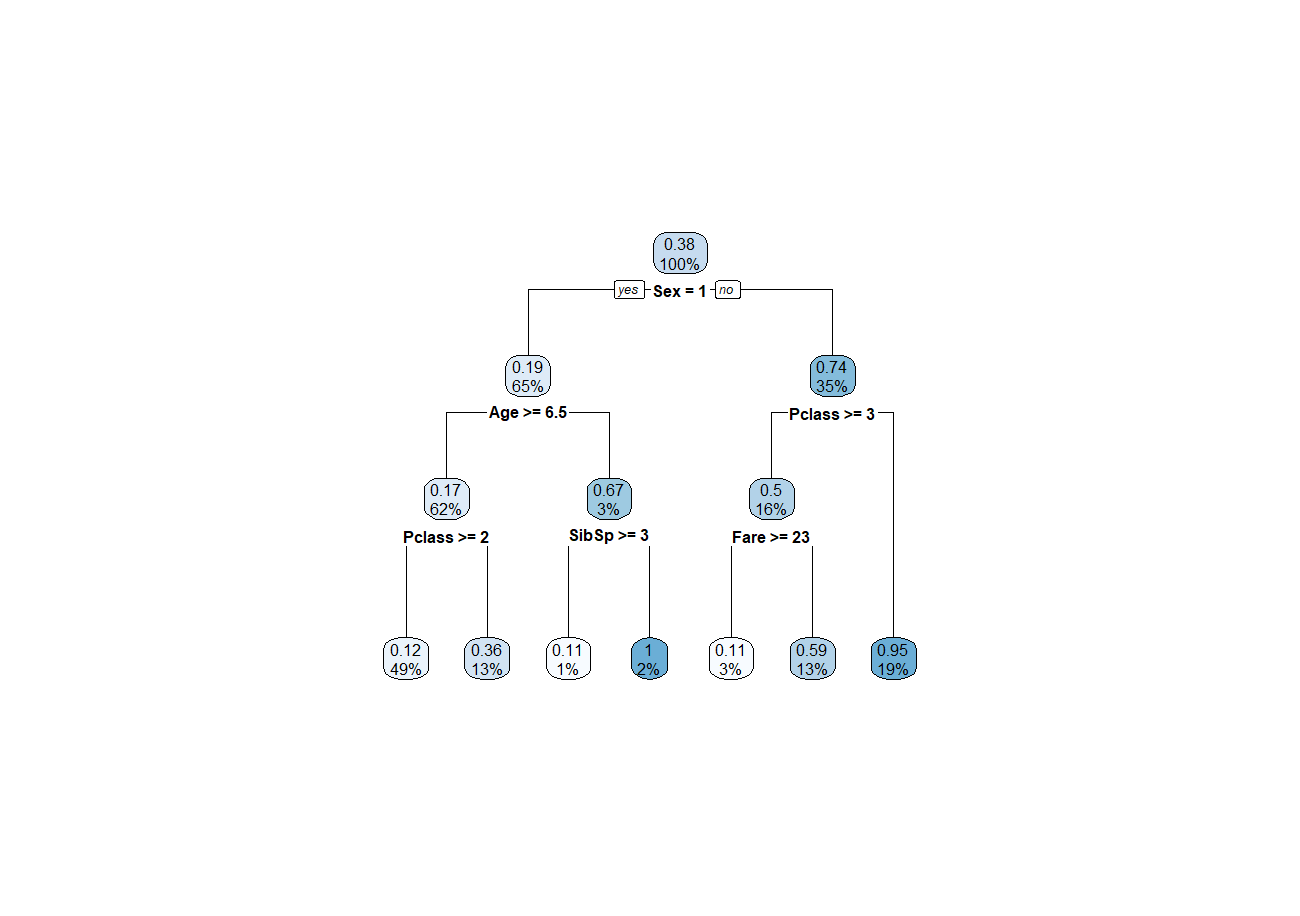
Video 3 – Árbol de decisión
Finalmente podemos concluir que nuestro modelo de árbol de decisión es un poco mejor que nuestro modelo basado en la regresión logisitca. Aquí acabamos esta práctica de R con el dataset del Titanic donde de una manera no muy complicada podemos adentrarnos en el mundo del machine learning .
Jorge Calvo
Profesor y Responsable de Tecnología e Innovación en Colegio Europeo de Madrid -- Asesor y Formador Tecnología Educativa -- CoFundador EuropeanValley Institución