¿Qué puede tener en común el libro del Quijote con la Inteligencia Artificial?. ¿Cómo una IA puede aprenderse el Quijote y crear un texto contextualizado en él? . Estas preguntas las vamos a explicar en este articulo y descender de una forma sencilla como detrás de esa inteligencia artificial «literaria» se esconde una razón matemática
El objetivo de este articulo es mostrar de una manera visual y sencilla como un modelo de Deep Learning puede predecir o crear un nuevo texto en función a un aprendizaje previo.
En este caso hemos usado un modelo propio pre-entrenado con los 50 primeros capítulos del Quijote. Este aprendizaje le ha dado el suficiente conocimiento para poder crear un texto contextualizado en base a una frase dada por nosotros.
Sin entrar en muchos detalles técnicos sobre el modelo, ya que no es el objetivo de este articulo, fue creado usando #Python y la librería #Tensorflow. Los pasos de creación fueron
- Adquirir el libro del Quijote en formato digital. https://www.gutenberg.org/ebooks/search/?query=quijote&submit_search=Go%21
- Tratamiento de los datos. (Tokenización)
- Creación del modelo usando redes LSTM (Large Short Term Memory)
- Entrenamiento
- Resultados y validación
- Predicción
- Salvar modelo
¿Donde esta la magia?
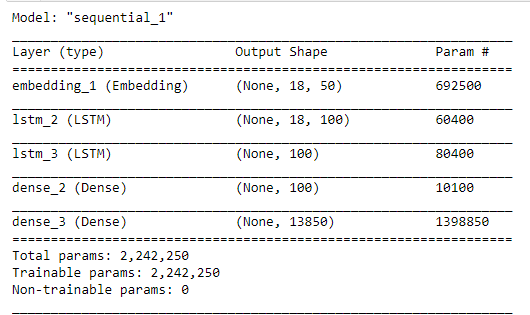
Realmente no hay magia, el modelo ha sido capaz de buscar y aprender patrones en su entrenamiento donde le permite predecir la siguiente palabra en función a una dada. Pero… ¿Cómo elige la siguiente palabra?. Pues la elige por cercanía, es decir la palabra que este más cerca a la que tiene previamente basada en una matriz de pesos como esta..
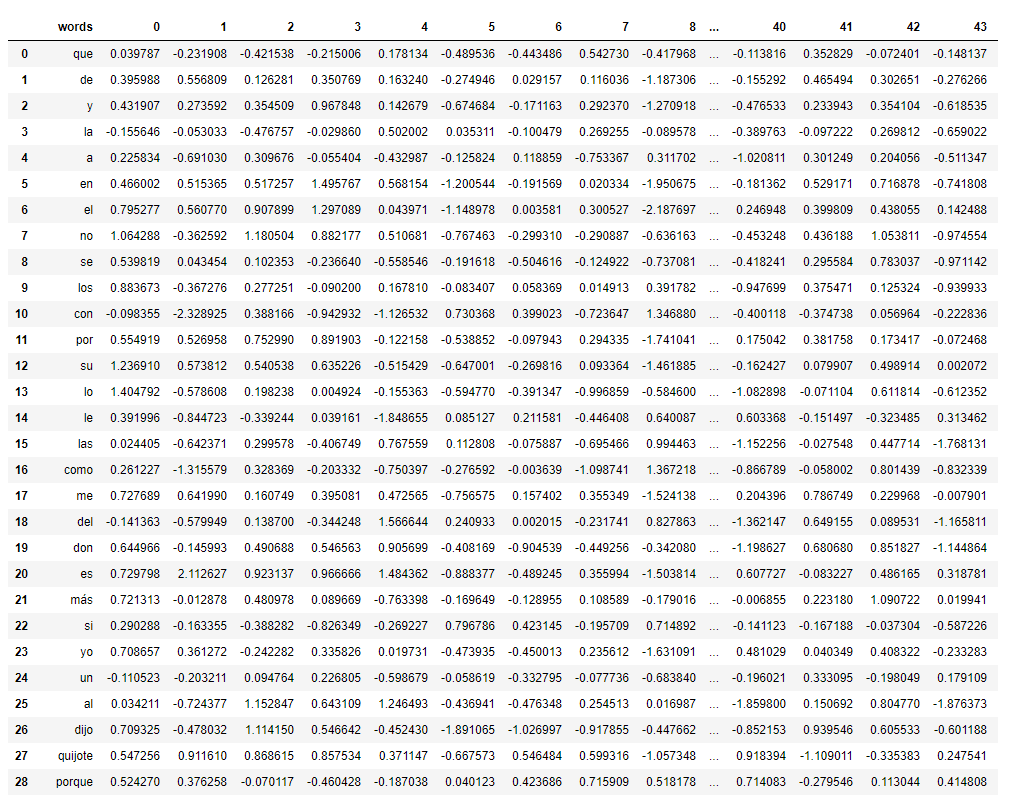
Esta matriz de pesos tiene en sus filas (instancias) todas las palabras únicas en los 50 primeros capítulos del Quijotes, unas 14.000 aproximadamente. ¿Qué son las columnas?. Pues las 50 columnas son las posibles salidas de nuestra red neuronal, ya que si os acordáis en los primeros párrafos de este articulo hablamos de que nuestro modelo de Deep Learning predecía un texto de 50 palabras en función a unas dadas por nosotros.
Ahora que tenemos estos datos podemos convertir esos pesos en distancia, y es en este punto donde vamos a representarlo visualmente, usando para ello la programación y las matemáticas.
Empezamos
Para poder hacer una representación en 2 dimensiones, debemos ayudarnos de la técnica del análisis de componentes principales (PCA), porque lógicamente nuestro vector de pesos de la red neuronal está formado por 50 dimensiones (50 columnas), exactamente el número de la capa de salida, es decir las palabras que se van a crear.
Como es imposible graficar en 50 dimensiones debemos reducir la dimensionalidad intentando perder la menor cantidad de información posible, por eso usaremos PCA.
¿Que es PCA?
Es una técnica de transformación lineal simple pero popular y útil que se utiliza en numerosas aplicaciones, como predicciones del mercado de valores, análisis de datos de expresión génica y muchas más. El objetivo es reducir las dimensiones de un conjunto de datos d-dimensionales al proyectarlo en un subespacio (k) -dimensional (donde k <d) para aumentar la eficiencia computacional mientras se retiene la mayor parte de la información.
- Estandarizar los datos.
- Obtenga los vectores propios y los valores propios de la matriz de covarianza o matriz de correlación, o realice la descomposición vectorial singular.
- Ordene los valores propios en orden descendente y elija los k vectores propios que corresponden a los k valores propios más grandes donde k es el número de dimensiones del nuevo subespacio de entidad (k≤d) /.
- Construya la matriz de proyección W a partir de los k vectores propios seleccionados.
- Transforme el conjunto de datos original X a través de W para obtener un subespacio de entidad k-dimensional Y.
Todo este calculo se puede realizar de forma manual pero para este articulo hemos usado la libreria de scikit-learn para automatizar el proceso.
Si queréis ver como todo este calculo se puede realizar de forma matemática usando Python, lo tengo programado en el notebook del proyecto subido en github aquí
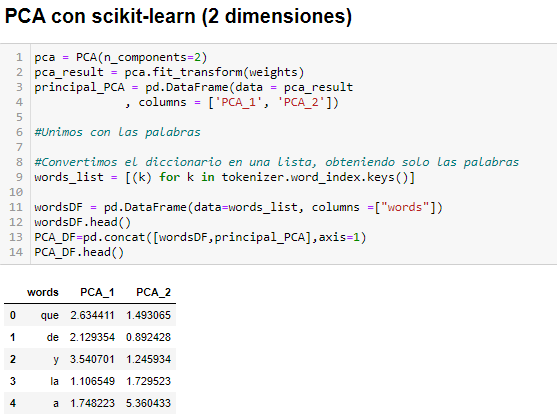
Explicamos el código
Lo que hacemos en las tres primeras líneas de nuestra celda de programación es crear el objeto PCA pasándole como condición la creación de 2 componentes, recordar debemos representar en 2 dimensiones. Después transformamos los pesos en solo dos columnas usando PCA y finalmente creamos un dataset con los resultados y marcando como columnas los dos componentes principales creados (PCA_1 y PCA_2)
La siguientes líneas del código es unir ese dataset de componentes principales con el de la lista de palabras, para que cada palabra corresponda con su PCA_1 y PCA_2 correspondiente.
La variable weights que he usado para entrenar el objeto PCA son los pesos de mi modelo, los cuales podéis sacarlos fácilmente de un modelo pre-entrenado usando
e = model.layers[0] weights = e.get_weights()[0]
Una vez que tenemos todas las palabras del Quijote establecidas en relación a dos variables ya podemos hacer un gráfico.
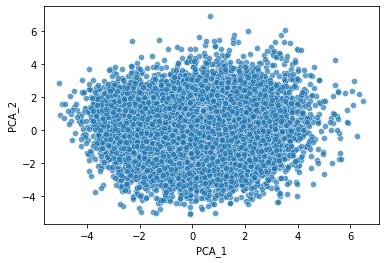
¿Podemos saber la distancia que hay entre ellas?
Claro, ahora matemáticamente podemos usar por ejemplo la Distancia Euclídea para saber cuanto están de lejos unas palabras respecto de las otras. Por ejemplo mirar este caso práctico realizado para saber la distancia de las palabras, respecto a la palabra «Quijote»
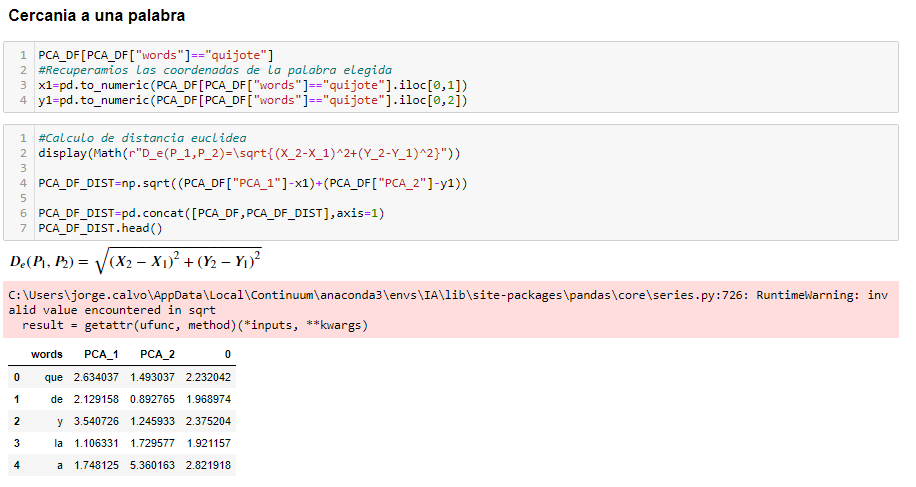
La columna «0» nos muestra la distacia de esa palabra con respecto a «Quijote»
Se puede observar que si en esa matriz buscamos la palabra «Quijote» (la ponemos en minúscula para facilitar el entrenamiento del modelo) su distancia euclídea es 0
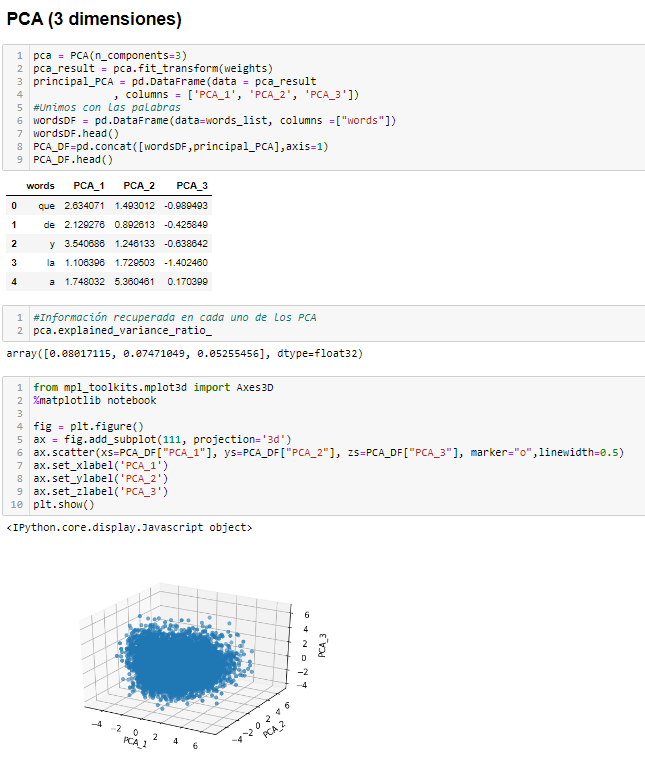
Y en 3 Dimensiones…
Por supuesto, simplemente debemos crear nuestro PCA y quedarnos con 3 Componentes principales, en vez de dos como en el caso anterior. De esta forma será aún más preciso porque se pierde menos información al reducir una dimensionalidad menos.
Aqui tenéis el ejemplo realizado en Python
Y ahora podemos visualizarlo mejor…
Una vez que ya hemos explicado como realmente se puede visualizar los datos de una predicción de texto en un modelo de Deep Learning, no vamos ayudar del proyecto TensorBoard de Tensorflow donde nos permitirá hacer una visualización muy interactiva de nuestros datos, usando exactamente las técnicas que acabamos de explicar.
Realmente este es el objetivo de este articulo, explicar de una manera visual y sin entrar en muchos detalles específicos (aunque alguno ha caído) de como la predicción o creación de un texto por parte de una inteligencia artificial tiene su base en una razón matemática y algorítmica que hemos visualizado para entender de una forma sencilla. Por supuesto si queréis saber más sobre este artículo o detalles podéis acceder al proyectop completo en mi github
https://github.com/jmcalvomartin/python/tree/master/projects/Quijote_NLP
Aquí tenéis un video de como ha quedado y también el enlace hacia la web interactiva para que podáis usarlo vosotros mismos.
Pruébalo tu mismo: Visualización en 3Dimensiones Quijote
Jorge Calvo
Profesor y Responsable de Tecnología e Innovación en Colegio Europeo de Madrid -- Asesor y Formador Tecnología Educativa -- CoFundador EuropeanValley Institución