Proceso de Lenguaje Natural (NLP)
Una Inteligencia Artificial que pueda comprender en su contexto el lenguaje natural y que sea capaz de comunicarse en cualquier idioma. Esto que no suena a ciencia ficción aún no es posible pero el progreso reciente en el aprendizaje automático (ML) y el procesamiento del lenguaje natural (NLP) indica que nos estamos acercando mucho a estas capacidades de enseñanza en lo que respecta al lenguaje natural.
Que una máquina posea capacidades a nivel humano es muy complicado, dado lo complejo que es entender el lenguaje. Sin embargo, el progreso reciente en NLP muestra resultados impresionantes como el que hablaremos en este articulo.
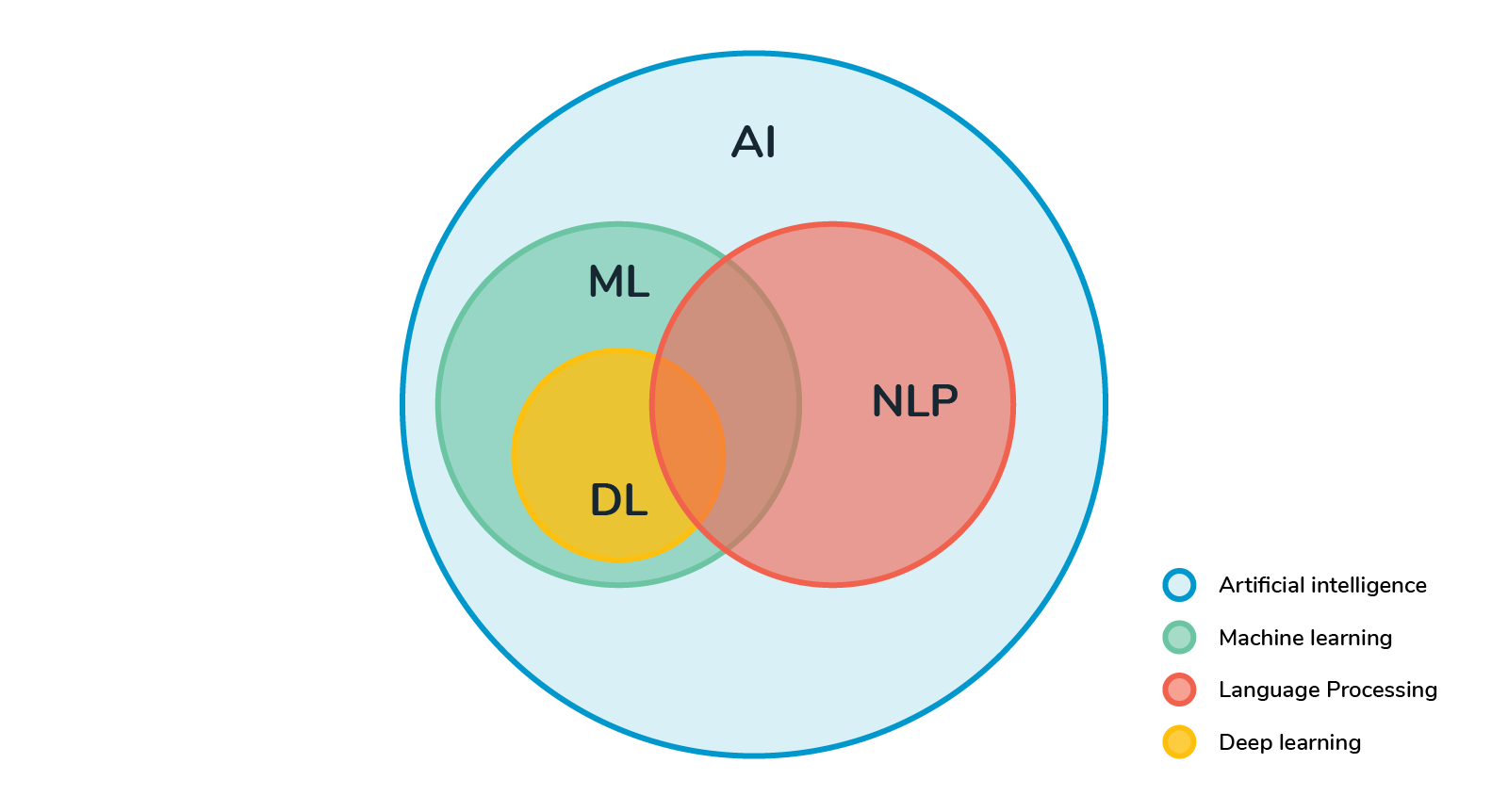
El aprendizaje por transferencia es el proceso de entrenar un modelo en un conjunto de datos a gran escala y luego usar ese modelo previamente entrenado para llevar a cabo el aprendizaje para otra tarea posterior (es decir, la tarea objetivo). El aprendizaje por transferencia se popularizó en el campo de la visión por computadora gracias al conjunto de datos ImageNet. En este articulo nos centraremos en cómo se aplican estos conceptos al campo del procesamiento del lenguaje natural.
Nos hemos vuelto muy buenos para predecir un resultado muy preciso con muy buenos modelos de entrenamiento. Pero debemos considerar que la mayoría de las tareas que realizamos con estos modelos no son nada generalistas, si no al contrario, son especificas de un solo objetivo o dominio. El mundo real no esta encerrado en el conjunto de datos que entrenamos, si no que es algo mucho más extenso y desordenado, por lo tanto ese modelo que hemos entrenado anteriormente si lo usamos para un objetivo mas general con toda seguridad su eficacia descenderá notablemente.
El aprendizaje transferido es la aplicación que se obtiene de un contexto a otro contexto. Aplicar el conocimiento de un modelo podría ayudar a reducir el tiempo de capacitación y los problemas de aprendizaje profundo al tomar los parámetros existentes para resolver problemas de datos “pequeños”.
Cuales son esas ventajas
- Requisitos de formación más simples utilizando datos previamente entrenados
- Requisitos de memoria mucho más pequeños
- Entrenamiento del modelo de destino considerablemente más corto: segundos en lugar de días
- Estos modelos permiten un mayor rendimiento con menos datos.
- Son más fáciles de usar que los modelos tradicionales de aprendizaje profundo, por lo que no requieren un científico de datos con especialización en NLP
Un aspecto miuy importante en el aprendizaje por transferencia es elegir el modelo preentrenado para nuestra tarea concreta, para ello quiero mostraros los modelos más populares usados para estas funciones de aprendizaje. Son modelos creados por grandes compañias como Google, Facebook, OpenAI, etc… modelos que necesitan grandes cantidades de datos y sobre todo mucha potencia y tiempo de computación.
Algunos de estos modelos son:
ELMo
( Embeddings from Language Models)
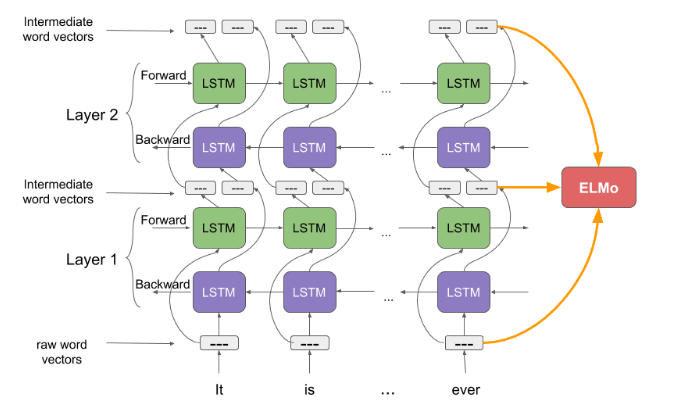
ELMo es una forma novedosa de representar palabras en vectores o incrustaciones. Estas incrustaciones de palabras son útiles para lograr grandes resultados en varias tareas de NLP. Los vectores de palabras de ELMo se calculan sobre un modelo de lenguaje bidireccional de dos capas (biLM) usando las llamadas redes recurrentes LSTM (Long Short Memory). Este modelo biLM tiene dos capas apiladas y cada capa tiene 2 pasos, hacia adelante y hacia atrás, donde de esta manera se produce el aprendizaje contextual de las palabras
GPT3
OpenAI Transformers
GPT-3 es un modelo de lenguaje impulsado por redes neuronales.
Como la mayoría de los modelos de lenguaje, GPT-3 está elegantemente entrenado en un conjunto de datos de texto sin etiqueta (en este caso, los datos de entrenamiento incluyen, entre otros, Common Crawl y Wikipedia). Las palabras o frases se eliminan aleatoriamente del texto y el modelo debe aprender a completarlas usando solo las palabras circundantes como contexto. Es una tarea de entrenamiento simple que da como resultado un modelo poderoso y generalizable.
La propia arquitectura del modelo GPT-3 es una red neuronal basada en transformers. Esta arquitectura se hizo popular hace alrededor de 2 a 3 años y es la base del popular modelo NLP BERT y el predecesor de GPT-3, GPT-2. Con 175 mil millones de parámetros, es el modelo de lenguaje más grande jamás creado (¡un orden de magnitud mayor que su competidor más cercano!), Y fue entrenado en el conjunto de datos más grande de cualquier modelo de lenguaje. Esta, al parecer, es la razón principal por la que GPT-3 es tan impresionantemente “inteligente”. Esto es lo que hace que GPT-3 sea tan emocionante para los profesionales del aprendizaje automático

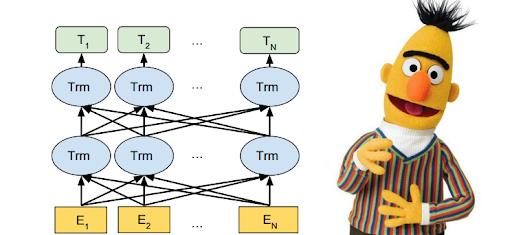
BERT
(Bidirectional Encoder Representations from Transformers)
La innovación técnica de BERT es aplicar la capacitación bidireccional de Transformer, un modelo de atención popular, al modelado de lenguaje. Esto contrasta con los esfuerzos anteriores que analizaban una secuencia de texto de izquierda a derecha o una formación combinada de izquierda a derecha y de derecha a izquierda. Los resultados de BERT muestran que un modelo que se entrena bidireccionalmente puede tener un sentido más profundo del contexto y flujo del lenguaje que los modelos de lenguaje unidireccionales. BERT utiliza Transformer, un mecanismo de atención que aprende las relaciones contextuales entre palabras (o subpalabras) en un texto. En su forma básica, Transformer incluye dos mecanismos separados: un codificador que lee la entrada de texto y un decodificador que produce una predicción para la tarea. Dado que el objetivo de BERT es generar un modelo de lenguaje, solo es necesario el mecanismo del codificador. El funcionamiento detallado de Transformer se describe en este documento de Google https://arxiv.org/pdf/1706.03762.pdf
A diferencia de los modelos direccionales, que leen la entrada de texto secuencialmente (de izquierda a derecha o de derecha a izquierda), el codificador Transformer lee la secuencia completa de palabras a la vez.
Hay tres formas en que podemos transferir el aprendizaje de los modelos preentrenados:
- Extracción de características: donde la capa preentrenada se usa para extraer solo características como usar BatchNormalization para convertir los pesos en un rango entre 0 y 1 con una media de 0. En este método, los pesos no se actualizan durante la retropropagación. Esto es lo que está marcado como no entrenable en el resumen del modelo.
- Ajuste fino(Fine Tuning): algo de lo que trata este articulo, donde BERT es ideal para esta tarea, porque está capacitado para responder preguntas. Por lo tanto, solo tenemos que ajustar el modelo para que se adapte a nuestro propósito. Tecnicamente Fine Tunning es el proceso en el que los parámetros de un modelo entrenado deben ajustarse con mucha precisión mientras intentamos validar ese modelo teniendo en cuenta un pequeño conjunto de datos que no pertenece al conjunto original.
- Extraer capas: en este método, extraemos solo las capas necesarias para la tarea, por ejemplo, es posible que deseemos extraer solo las capas de niveles inferiores en BERT para realizar tareas como POS, análisis de sentimientos, etc., donde solo se extraerían características de nivel de palabra.
Aplicar el aprendizaje por transferencia.
Para el aprendizaje por transferencia, generalmente tenemos dos pasos. Utilizar el conjunto de datos X para entrenar previamente su modelo y luego usaremos ese modelo previamente entrenado para llevar ese conocimiento a la resolución del conjunto de datos B. En este caso, BERT ha sido previamente entrenado en BookCorpus y Wikipedia y será el que usaremos para nuestra practica sobre un texto concreto, donde podremos hacerle preguntas para que usando un lenguaje natural, nos las pueda contestar de forma correcta.
Para ello usaremos el lenguaje de programación Python y la libreria de Machine Learning, Pytorch. Cargaremos nuestro modelo BERT preentrenado, que podemso encontrar en https://huggingface.co/models?filter=es y le pasaremos un texto sobre un tema concreto, por ejemplo la Biografía de Miguel Cervantes, el primer capitulo de Moby Dick o cualquier articulo que nos podamos encontrar en Internet. Nuestro modelo usará BERT para enteder el contexto del articulo que le hemos pasado y de esta manera poder contestar a preguntas que le hagamos en relación al mismo.
Por ejemplo preguntarle donde nacio Cervantes ó quien fueron sus hermanos o donde se alistó cuando era joven. La idea es que se puedan realizar preguntas con un lenguaje natural sin tener que especificar de fomar concreta o usar las mismas palabras que el texto aprendido por la IA.
Textos usados para la práctica: Cervantes y Moby Dick
Conclusión
Estamos ante un nuevo paradigma del conocido Natural Languaje Processing (NLP), Los avances recientes en la investigación han estado dominados por la combinación de métodos de aprendizaje por transferencia con modelos de lenguaje Transformers a gran escala.
La creación de estos modelos de propósito general sigue siendo un proceso costoso y lento que restringe el uso de estos métodos a un pequeño subconjunto de la comunidad de NLP. Con los Transformers, se produjo un cambio de paradigma, con la nueva idea para entrenar un modelo en una tarea posterior pasando de un modelo específico en blanco a una arquitectura preentrenada de propósito general.
A medida que NLP se convierta en un aspecto clave de la IA, la democratización de los Transformers abrirá más puertas a los investigadores emergentes. La opción de que se puede acceder a los modelos pre-entrenados de última generación como BERT sin tener que construirlos desde cero, dará una ventaja a los profesionales para que pueden enfocarse en su objetivo en lugar de reinventar grandes modelos.
Jorge Calvo
Profesor y Responsable de Tecnología e Innovación en Colegio Europeo de Madrid -- Asesor y Formador Tecnología Educativa -- CoFundador EuropeanValley Institución